Squash Non-Head Commits
If your commit has children, you have the option to use the squash commit command.
Squashing is a way to rewrite your commit history; this helps clean up and simplify your commit history before sharing your work with team members.
Squashing a commit in HPE Machine Learning Data Management means that you are combining all the file changes in the commits of a global commit into their children and then removing the global commit. This behavior is inspired by the squash option in git rebase. No data stored in PFS is removed since they remain in the child commits.
pachctl squash commit <commit-ID>Example #
In the simple example below, we create three successive commits on the master branch of a repo repo:
- In commit ID1, we added files A and B.
- In commit ID2, we added file C.
- In commit ID3, the latest commit, we altered the content of files A and C.
We then run pachctl squash commit ID1, then pachctl squash commit ID2, and look at our branch and remaining commit(s).
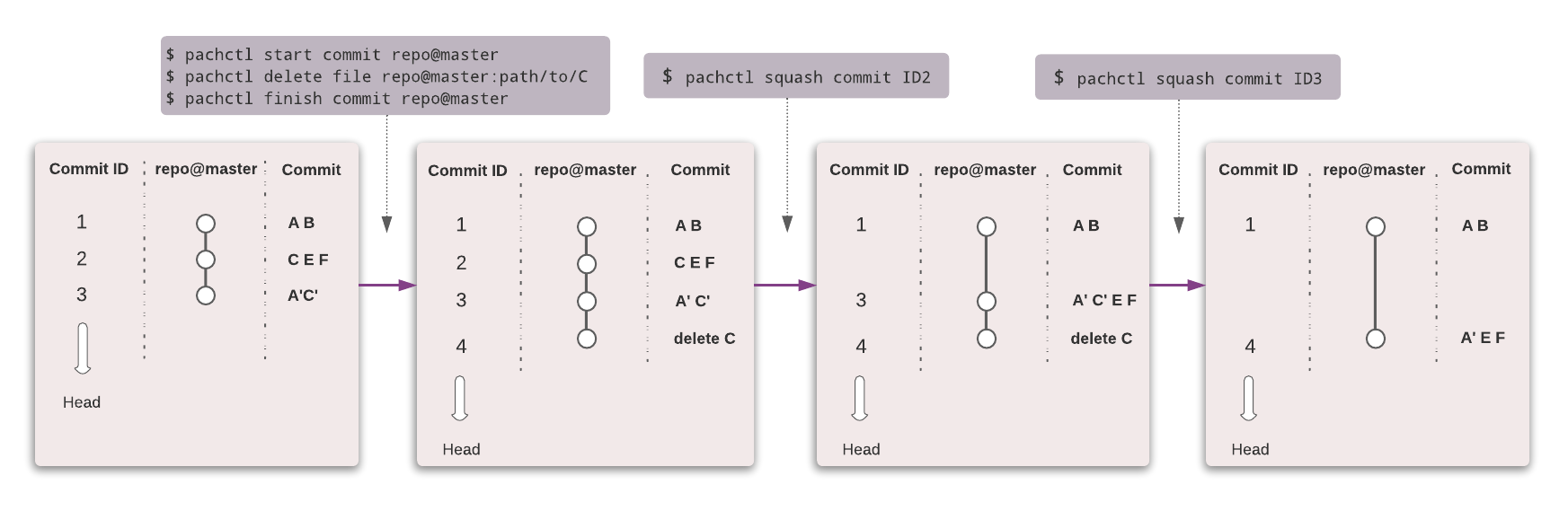
- A’ and C’ are altered versions of files A and C.
At any moment, pachctl list file repo@master invariably returns the same files A’, B, C’. pachctl list commit however, differs in each case, since, by squashing commits, we have deleted them from the branch.
Considerations #
- Squashing a global commit on the head of a branch (no children) will fail. Use
pachctl delete commitinstead. pachctl squash commitstops (but does not delete) associated jobs.
Limitations #
- Squash commit only applies to user repositories. For example, you cannot squash a commit that updated a pipeline (Commit that lives in a spec repository).
- You cannot squash a commit set that contains a commit that is a dependency for another commit set. For example, if you have
RepoB@masterthat depends onRepoA@masteras an input, you cannot squash the commit set forRepoA@master.