Intro to Pipelines
Introduction to Pipelines #
The HPE Machine Learning Data Management Pipeline System (PPS) is a powerful tool for automating data transformations. With PPS, pipelines can be automatically triggered whenever input data changes, meaning that data transformations happen automatically in response to changes in your data, without the need for manual intervention.
Pipelines in HPE Machine Learning Data Management are defined by a pipeline specification and run on Kubernetes. The output of a pipeline is stored in a versioned data repository, which allows you to reproduce any transformation that occurs in HPE Machine Learning Data Management.
Pipelines can be combined into a computational DAG (directed acyclic graph), with each pipeline being triggered when an upstream commit is finished. This allows you to build complex workflows that can process large amounts of data efficiently and with minimal manual intervention.
Pipeline Specification #
This is a HPE Machine Learning Data Management pipeline definition in YAML. It describes a pipeline called transform that takes data from the data repository and transforms it using a Python script my_transform_code.py.
pipeline:
name: transform
input:
pfs:
repo: data
glob: "/*"
transform:
image: my-transform-image:v1.0
cmd:
- python
- "/my_transform_code.py"
- "--input"
- "/pfs/data/"
- "--output"
- "/pfs/out/"Here’s a breakdown of the different sections of the pipeline definition:
- pipeline specifies the name of the pipeline (in this case, it’s transform). This name will also be used as the name for the output data repository.
- input specifies the input for the pipeline. In this case, the input is taken from the
datarepository in HPE Machine Learning Data Management.globis used to specify how the files from the repository map to datums for processing. In this case,/*is used to specify all files in the repository can be processed individually. - transform specifies the code and image to use for processing the input data. The
imagefield specifies the Docker image to use for the pipeline. In this example, the image is namedmy-transform-imagewith a tag ofv1.0. Thecmdfield specifies the command to run inside the container. In this example, the command ispython /my_transform_code.py, which runs a Python script namedmy_transform_code.py. The script is passed the--inputflag pointing to the input data directory, and the--outputflag pointing to the output data directory./pfs/data/and/pfs/out/are directories created by HPE Machine Learning Data Management. The input directory will contain an individual datum when the job is running, and anything put into the output directory will be committed to the output repositories when the job is complete.
So, in summary, this pipeline definition defines a pipeline called transform that takes all files in the data repository, runs a Python script to transform them, and outputs the results to the out repository.
Datums and Jobs #
Pipelines can distribute work across a cluster to parallelize computation. Each time data is committed to a HPE Machine Learning Data Management repository, a job is created for each pipeline with that repo as an input to process the data.
To determine how to distribute data and computational work, datums are used. A datum is an indivisible unit of data required by the pipeline, defined according to the pipeline spec. The datums will be distributed across the cluster to be processed by workers.
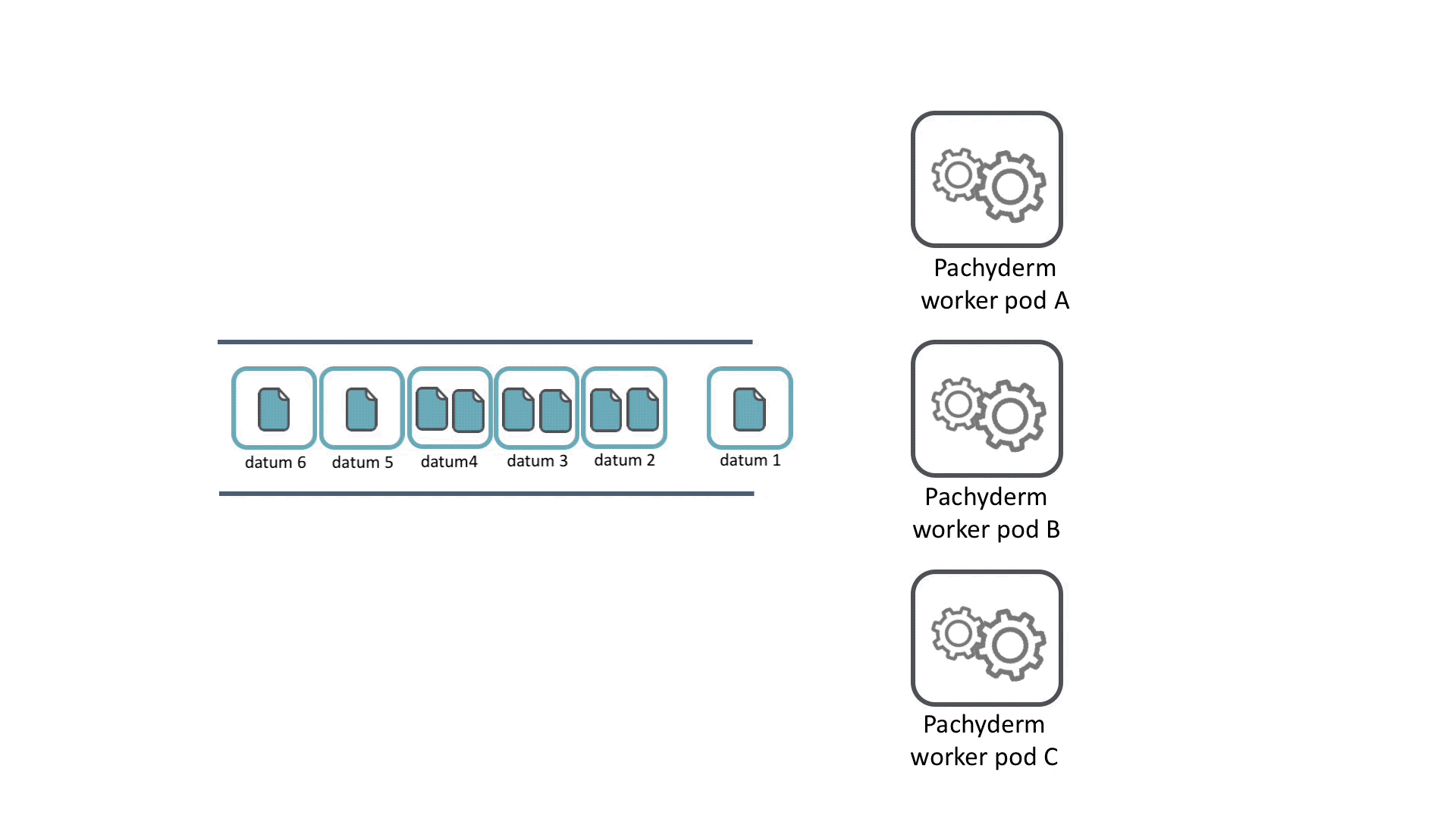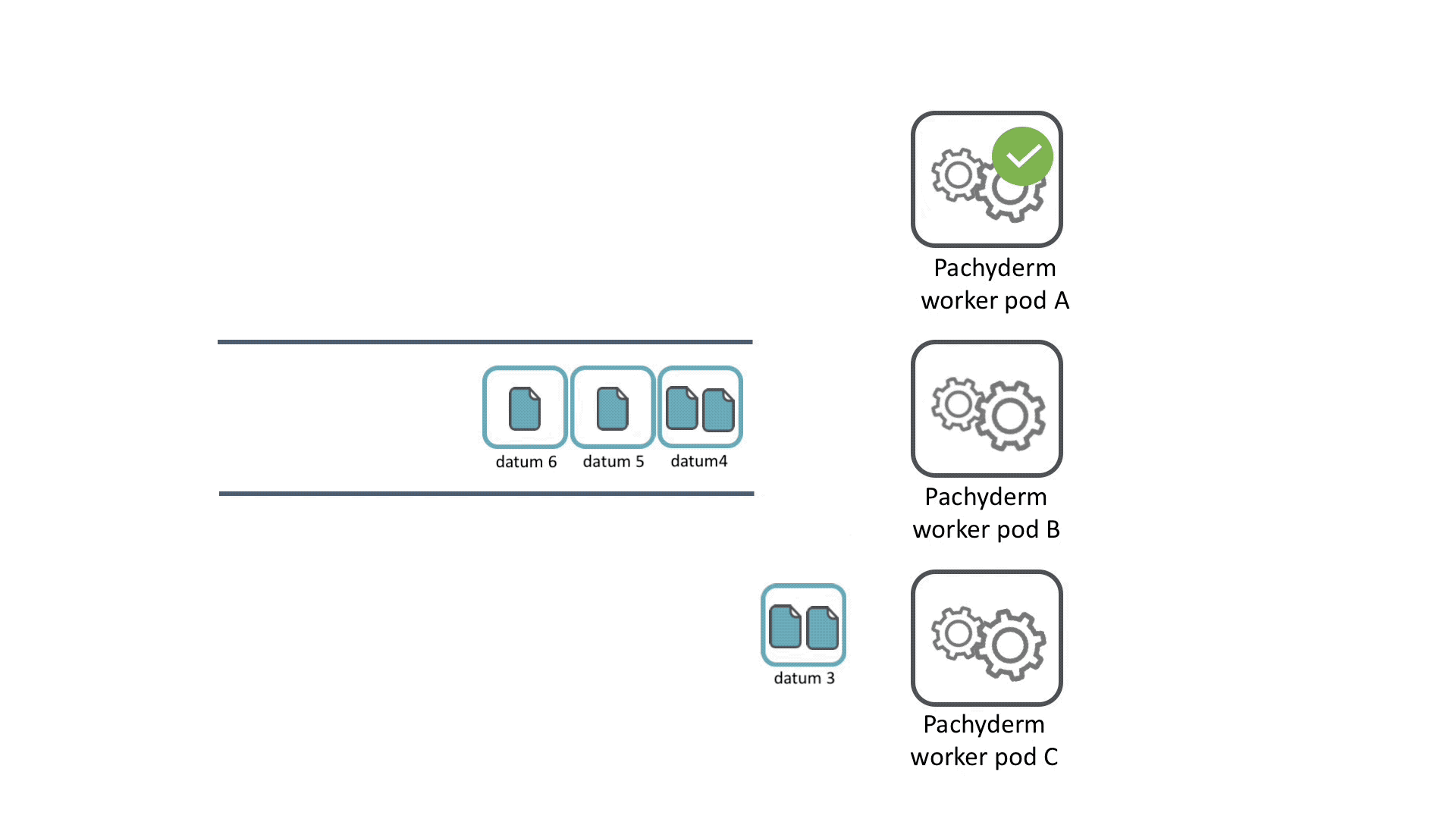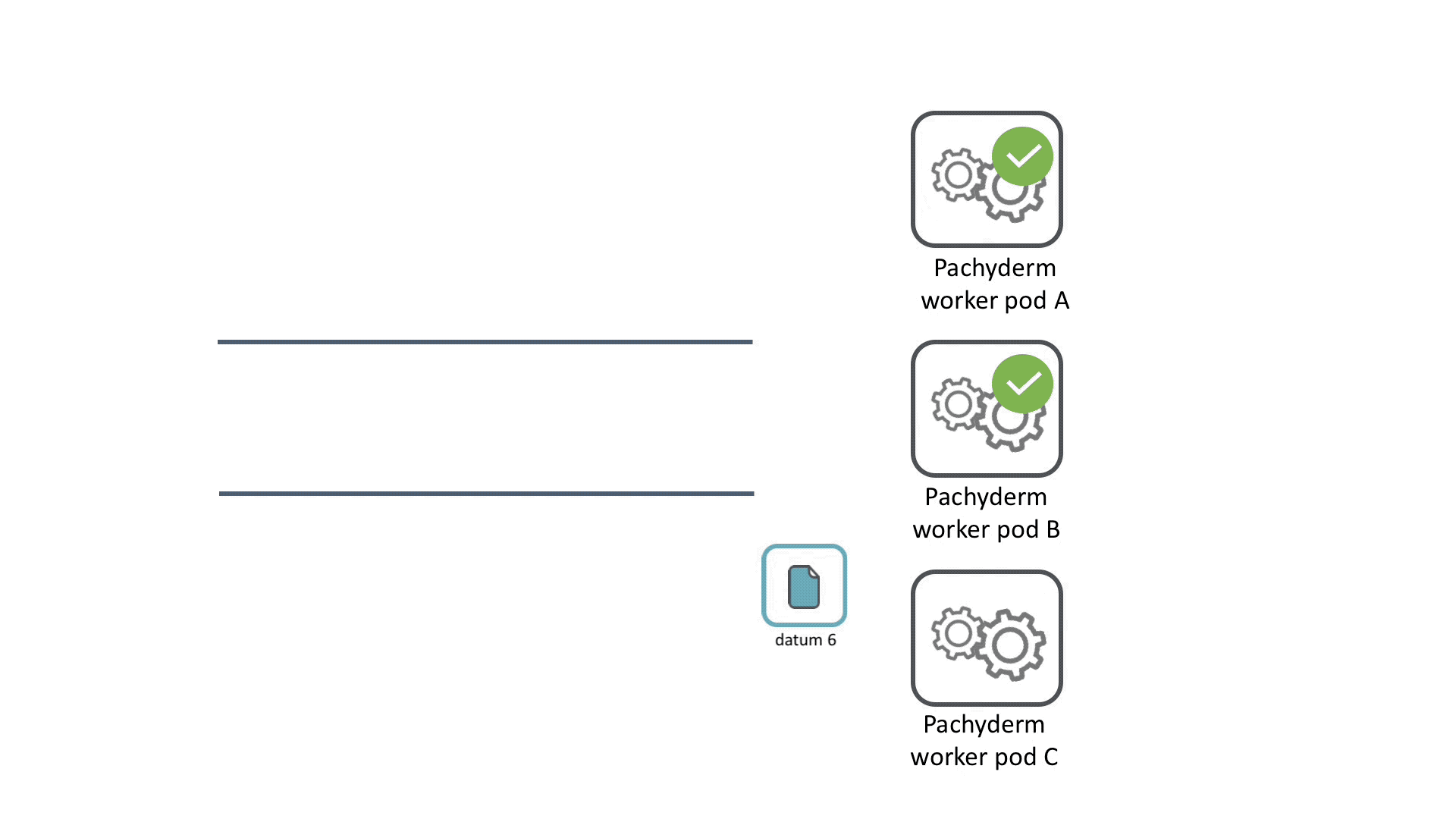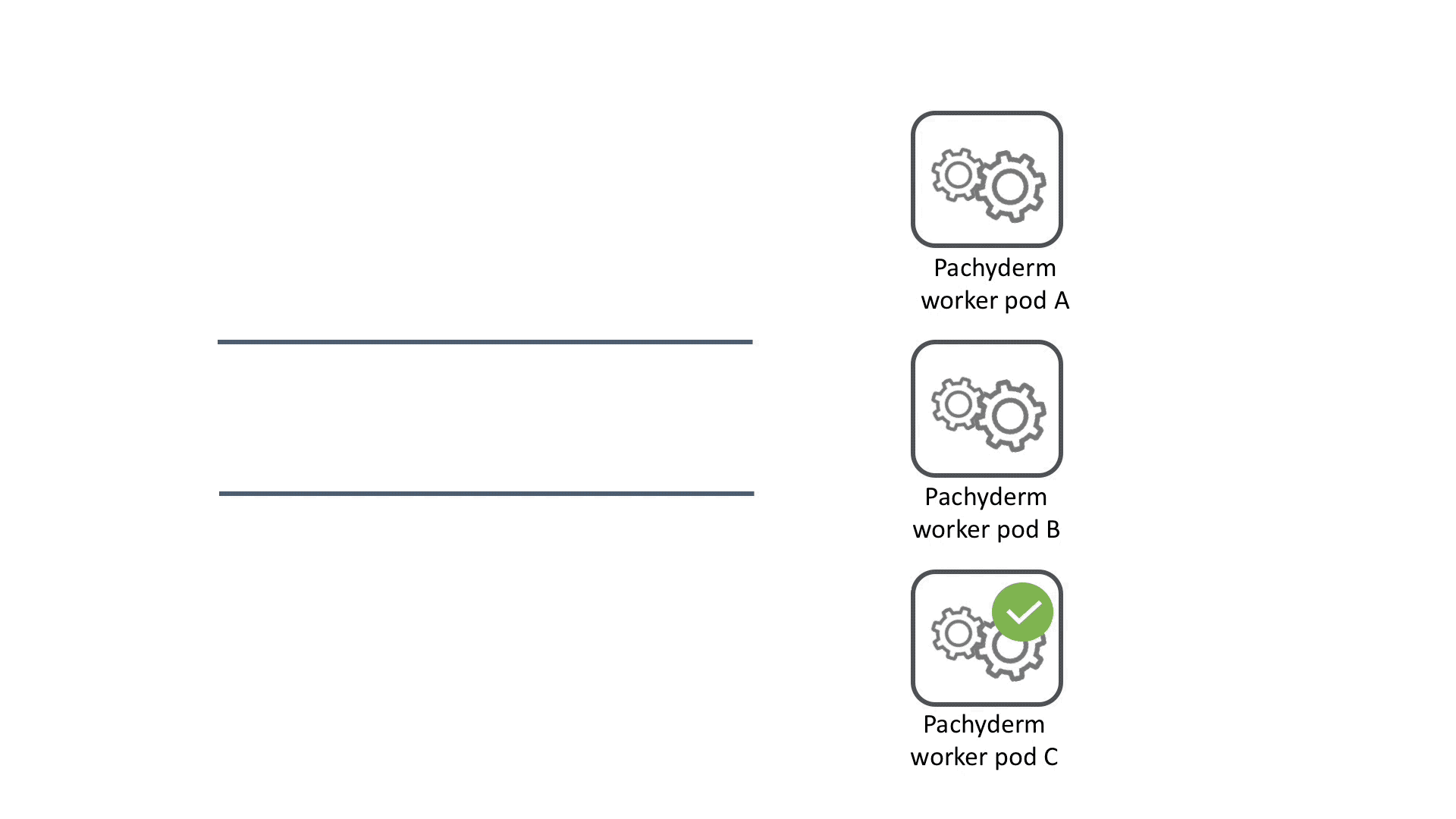
For example, say you have a bunch of images that you want to normalize to a single size. You could iterate through each image and use opencv to change the size of it. No image depends on any other image, so this task can be parallelized by treating each image as an individual unit of work, a datum.
Next, let’s say you want to create a collage from those images. Now, we need to consider all of the images together to combine them. In this case, the collection of images would be a single datum, since they are all required for the process.
HPE Machine Learning Data Management input specifications can handle both of these situations with the glob section of the Pipeline Specification.
Basic Glob Patterns #
In this section we’ll introduce glob patterns and datums in a couple of examples.
In the basic glob pattern example below, the input glob pattern is /*. This pattern matches each image at the top level of the images@master branch as an individual unit of work.
pipeline:
name: resize
description: A pipeline that resizes an image.
input:
pfs:
glob: /*
repo: images
transform:
cmd:
- python
- resize.py
- --input
- /pfs/images/*
- --output
- /pfs/out/
image: pachyderm/opencvWhen the pipeline is executed, it retrieves the datums defined in the input specification. For each datum, the worker downloads the necessary files into the Docker container at the start of its execution, and then performs the transform. Once the execution is complete, the output for each execution is combined into a commit and written to the output data repository.
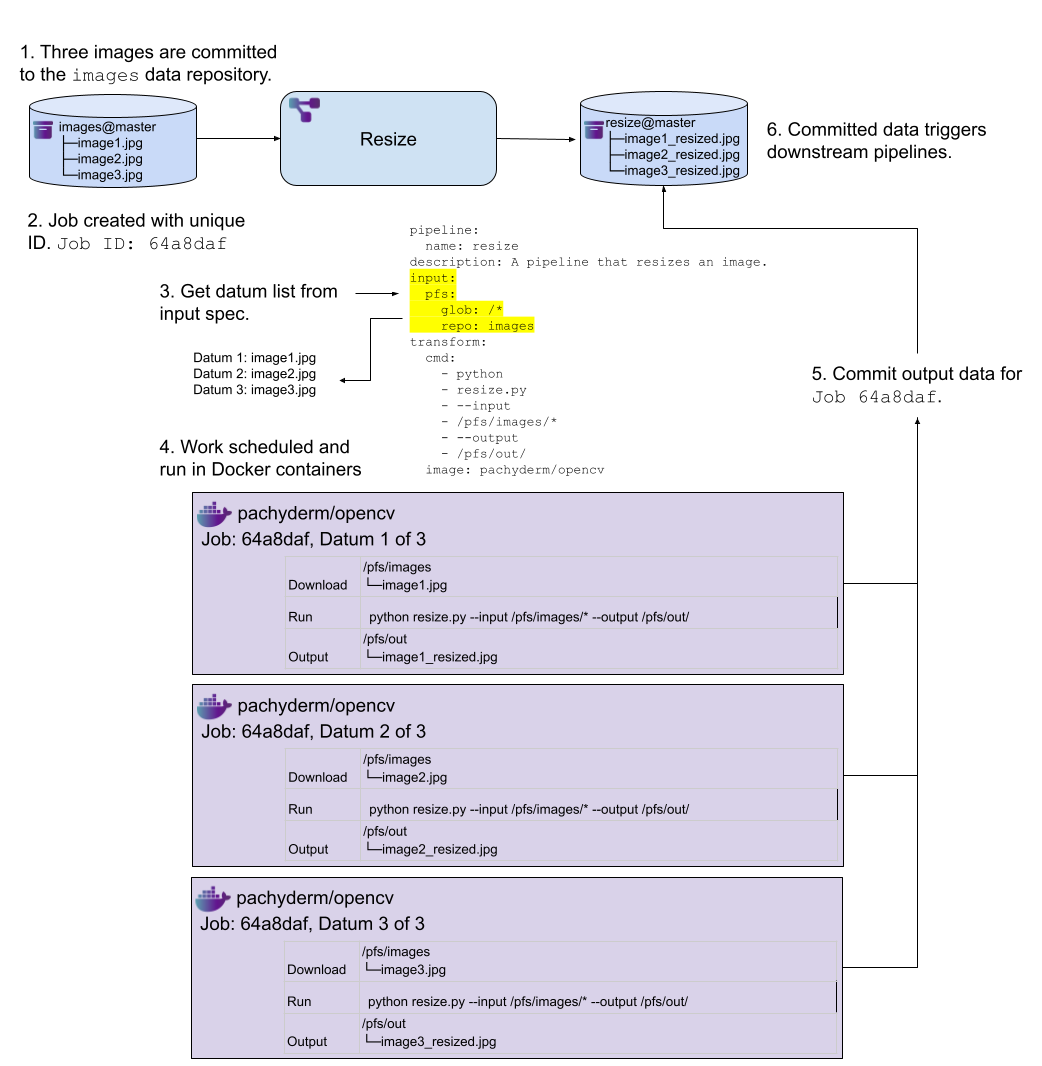
In this example, the input glob pattern is /. This pattern matches everything at the top level of the images@master branch as an individual unit of work.
pipeline:
name: collage
description: A pipeline that creates a collage for a collection of images.
input:
pfs:
glob: /
repo: images
transform:
cmd:
- python
- collage.py
- --input
- /pfs/images/*
- --output
- /pfs/out/
image: pachyderm/opencvWhen this pipeline runs, it retrieves a single datum from the input specification. The job runs the single datum, downloading all the files from the images@master into the Docker container, and performs the transform. The result is then committed to the output data repository.
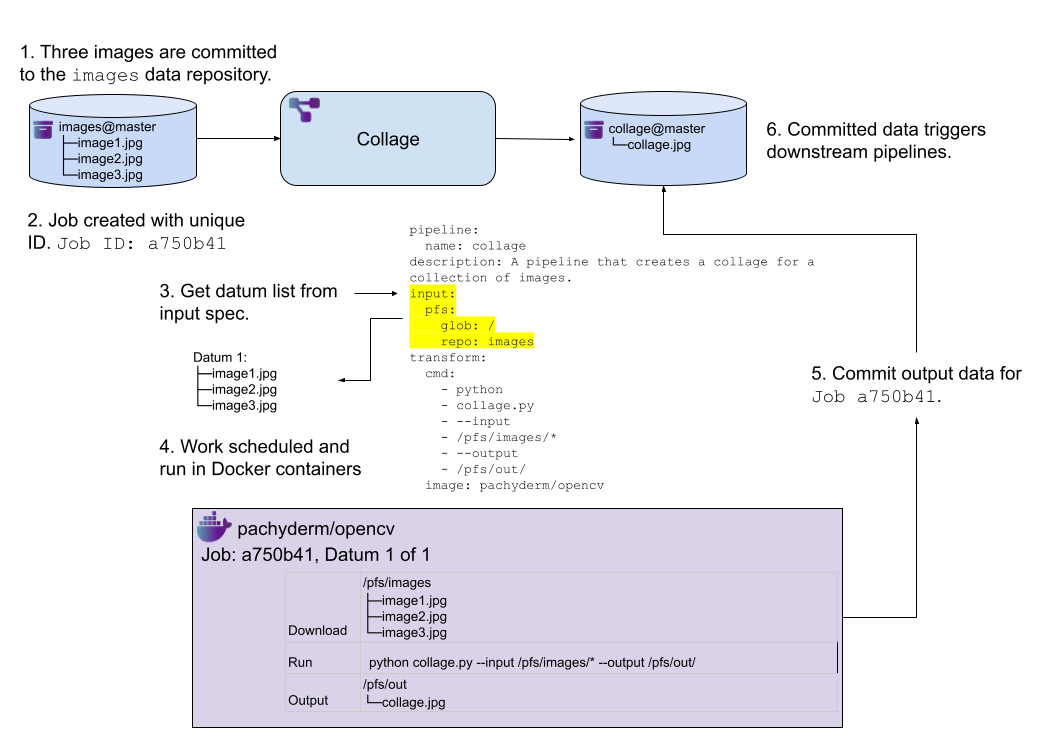
Advanced Glob Patterns #
Datums can also be created from advanced operations, such as Join, Cross, Group, Union, and others to combine glob patterns from multiple data repositories. This allows us to create complex datum definitions, enabling sophisticated data processing pipelines.
Pipeline Communication (Advanced) #
A much more detailed look at how HPE Machine Learning Data Management actually triggers pipelines is shown in the sequence diagram below. This is a much more advanced level of detail, but knowing how the different pieces of the platform interact can be useful.
Before we look at the diagram, it may be helpful to provide a brief recap of the main participants involved:
- User: The user is the person interacting with HPE Machine Learning Data Management, typically through the command line interface (CLI) or one of the client libraries.
- PFS (HPE Machine Learning Data Management File System): PFS is the underlying file system that stores all of the data in HPE Machine Learning Data Management. It provides version control and lineage tracking for all data inside it.
- PPS (HPE Machine Learning Data Management Pipeline System): PPS is how code gets applied to the data in HPE Machine Learning Data Management. It manages the computational graph, which describes the dependencies between different steps of the data processing pipeline.
- Worker: Workers are Kubernetes pods that executes the jobs defined by PPS. Each worker runs a container image that contains the code for a specific pipeline. The worker will iterate through the datums it is given and apply user code to it.
sequenceDiagram participant User participant PPS participant PFS participant Worker User->>PFS: pachctl create repo foo activate PFS Note over PFS: create branch foo@master deactivate PFS User->>PPS: pachctl create pipeline bar activate PPS PPS->>PFS: create branch bar@master
(provenant on foo@master) PPS->>Worker: create pipeline worker master Worker->>PFS: subscribe to bar@master
(because it's subvenant on foo@master) deactivate PPS User->>PFS: pachctl put file -f foo@master data.txt activate PFS Note over PFS: start commit PFS->>PFS: propagate commit
(start downstream commits) Note over PFS: copy data.txt to open commit Note over PFS: finish commit PFS-->>Worker: subscribed commit returns deactivate PFS Note over Worker: Pipeline Triggered activate Worker Worker->>PPS: Create job Worker->>PFS: request datums for commit PFS-->>Worker: Datum list loop Each datum PFS->>Worker: download datum Note over Worker: Process datum with user code Worker->>PFS: copy data to open output commit end Worker->>PFS: Finish commit Worker->>PPS: Finish job deactivate Worker
This diagram illustrates the data flow and interaction between the user, the HPE Machine Learning Data Management Pipeline System (PPS), the HPE Machine Learning Data Management File System (PFS), and a worker node when creating and running a HPE Machine Learning Data Management pipeline. Note, this is simplified for the single worker case. The multi-worker and autoscaling mechanisms are more complex.
The sequence of events begins with the user creating a PFS repo called foo and a PPS pipeline called bar with the foo repo as its input. When the pipeline is created, PPS creates a branch called bar@master, which is provenant on the foo@master branch in PFS. A worker pod is then created in the Kubernetes cluster by PPS, which subscribes to the bar@master branch.
When the user puts a file named data.txt into the foo@master branch, PFS starts a new commit and propagates the commit, opening downstream commits for anything impacted. The worker receives the subscribed commit and when it finishes, triggers the pipeline.
The triggered pipeline creates a job for the pipeline, requesting datums for the output commit. For each datum, the worker downloads the data, processes it with the user’s code, and writes the output to an open output commit in PFS. Once all datums have been processed, the worker finishes the output commit and the job is marked as complete.